

本文为论文翻译,查看英文论文请点击文末阅读原文链接
简介
作为一个并不全面的叙述者,我希望能借助历史上重要人物和他们的思想来讲述人工智能和机器学习是如何被发明的。
这篇文章中所讨论的人工智能是指“非人类”的智能,如果想要定义“非人类”的智能,就必须先定义人类智能。我认为人类智能是人类通过结合自然禀赋和后天习得实现的多种能力,识别信息和做出决策是非常突出的两种,其他还包括对时间和空间的认知,以及对他人的共情。一代又一代的人类从父母身上学习上一辈的技能和知识,又在此基础上创新出自己的技能和知识,最后把前人的遗产和自身的创新全都传给下一辈的孩子。在本文中我也会介绍伽利略·伽利雷(Galileo Galilei)和查尔斯·达尔文(Charles Darwin)是如何结合先天才能和后天习得创造出科学上的突破,并为现代的研究人员设计出能够识别信息和作出决策的人工智能埋下伏笔[1]。
我在这篇文章里提及了许多概念和技术,这对普通读者来说可能是新事物,但它们就像一棵棵树,组成了我希望能够描述清楚的机器学习这片“森林”。若有读者好奇地想了解更多复杂的“树”,我建议他们使用专业搜索引擎或查看本文结尾处参考文献中的内容。
人类智能
认知心理学家史蒂芬·平克(Steven Pinker)的书籍《白板》(The Blank Slate)的第13章题为《走出我们的深渊》(Out of Our Depths),在本章中,平克基于对人类认知障碍的研究为高中和大学应该教授什么学科提供了建议。他在开章中介绍了进化使我们自然擅长的一些技能,以及我们必须通过后天学习才能获取的其他技能。他认为,进化未赋予人类的技能在人类10万年的历史和史前史中并不重要。但是,现代生活发生了很多变化,有些进化未赋予我们的东西也变得前所未有地重要,平克就此总结出了四个此类学科:
1.物理学 关于重量、时间、空间、运动、能量、热和光的理论。
2.生物学 关于生命、出生和死亡的理论。
3.统计学 描述不确定性以及识别和解释相对频率的方法。
4.经济学 关于工作、生产、家庭、组织、分配、市场、价格和数量的理论。
现代生活中,只有对这四个领域有所掌握才能做出明智的个人决策和公共决策,但我们的“直觉”经常让我们在这些领域中犯错。出于行文目的,我暂且将“直觉”定义为我们进化出来的能够快速理解各种情况的思维方式,它的近义词可以是“常识”,即我们本能地就能够理解的东西。平克的研究介绍了在这四个领域中我们的直觉如何将我们引入歧途,如果不接受后天教育就无法有所改进。
借用平克的例子可以很好的说明我们的常识和直觉并不能帮助我们理解现代生活。在物理学领域,根据理查德·费曼(Richard Feynman)和其他杰出的物理学家的说法,常识难以帮助我们理解广义相对论和量子力学。统计学领域,经历过狩猎和采集生活时期的人类进化出了基础的计算能力,但是,相比从前需要用到计算能力的事件,现代生活中的重大风险事件发生的概率下降了很多,而我们还没有进化出妥善应对小概率事件的能力,仅凭直觉在公共决策中很难衡量小概率事件的成本和收益。经济学领域,进化教给了我们的祖先一套关于生产和交换的经济理论,然而这些理论并没能让我们理解劳动分工、分配、市场、中间商、中介、稳定市场的投机行为和利润。事实上,我们天生就误解了这些东西,这也是为什么会反复发生针对中间商和贸易商、投机者和流动性提供者的打压和大屠杀,这些受害者往往都是少数族裔。
上述认知缺陷为平克呼吁重新设计课程的建议提供了理论基础。平克将教育描述为一种补偿我们先天的认知限制和开发我们先天学习能力的技术。他呼吁对学术课程进行大刀阔斧的改革,更多地教授那些能帮助我们享受现代生活和做出正确决定的学科:生物学、统计学和经济学。他也承认,多教授这些学科意味着少教授其他学科。
2.1 人工智能和我们天生的认知极限
平克在同一章中还讲述了人类是如何寄希望于“人工智能”来补充并超越与生俱来的自然人类智能。这里潜藏着一个悖论,即创造人工智能和机器学习的主要技术工具来自物理学、生物学、统计学和经济学,而这些正是我们先天认知有限的领域。换句话说,我们试图利用自己天生不擅长的领域创造人工智能和机器学习。机器学习和人工智能的早期先驱和实践者通过透彻地学习以及富有想象力地使用已有的最优化分析技术,来弥补他们在自然认知方面的不足。
两位机器学习的先驱
3.1 伽利略
因为提倡地球围绕太阳旋转,17世纪初伟大的意大利数学家、科学家、物理学家、天文学家伽利略(1564-1642)最终被宗教裁判所逮捕。在被逮捕的许多年前,伽利略从事了一项研究,我认为这项研究展示了机器学习和人工智能的本质。伽利略的研究策略可以总结为以下四步:(1)设计并进行实验来收集数据;(2)反复观察数据,试图发现模式;(3)通过拟合一个函数来减少数据的维度;(4)将该函数解释为自然界的一般规律。
这就是著名的伽利略“斜面实验”以及他对数据进行的处理和降维。伽利略试图发现物体自由落体背后的自然规律。也许你在想“这很容易,只要应用艾萨克·牛顿(Isaac Newton)的万有引力定律就行了”。不要太着急下定论:牛顿这时候还没有出生。当时被广为接受的主流理论是亚里士多德(Aristotle)在2000年前的观点:较重的物体比较轻的物体下落得快。
伽利略尝试用实证方法来验证亚里士多德的观点。也许你会想:“为什么不直接扔下不同重量的球,以便测量它们下落的速度呢?”伽利略无法这样做,因为不论多重的球落下的速度都比当时的钟能准确测量的速度快得多。因此,伽利略决定建造不同角度的光滑斜面,并调整角度,使落下的球的速度足够慢,这样他就可以用他的时钟测量它们沿平面的移动速度。对于一个长度l和高度h的平面,比率 h/l 决定了平面的角度。伽利略扔下一个球,仔细测量了球沿平面移动的距离d,将之计作球被扔下后经过的时间t的函数。他做了一个有两栏的表格,其中记录了ti和di(i = 1,...n),n为他在每个实验中的测量次数。对于一个给定的实验,他将di和ti绘制在一起。他对各种不同重量的球进行了实验,设置了不同的l和h (即斜面的不同角度)。然后他凝视自己记录的图表,发现一个惊人的现象:在所有的图表中,行进的距离与经过的时间的平方成正比,与球的重量和斜面的角度无关。他推断出一个公式:
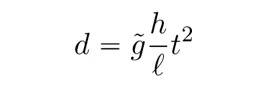
请注意,出人意料的是,球的重量不在右边的函数中。这就说明,球的下落速度显然是与它的重量无关。因此,通过对他的实验数据进行函数拟合,伽利略同时完成了数据降维和提炼概括。他发现了一个自然规律,这个规律成为50年后艾萨克·牛顿思想的一个重要启发。
伽利略的斜面实验具有现代机器学习和人工智能的所有要素。他一开始不知道世界是如何运作的,也没有一个好的理论。他所做的完全是无理论的。所以他进行了一系列的实验,收集了数据表,每个实验一个表,以球的重量以及斜面的长度l和高度h为索引。他从许多数据表中推导 (即“拟合”)出一个函数,结果发现这个函数只由一个新数字决定,即“参数” g ̃[2]。
我并不完全理解是什么启发了伽利略去设计他的实验,收集那些测量数据,并通过拟合函数来减少测量数据的维度。不过我确实知道伽利略拥有的工具,以及本可以帮助他、但他却没有的工具。尤其是,他不知道微分和积分计算——几十年后,这些工具才被费马(Fermat)、牛顿和莱布尼茨(Leibniz)发明出来。但伽利略确实非常了解几何和代数,也十分熟悉欧几里得(Euclid)和阿基米德(Archimedes)。如果没有这些工具,他的聪明才智和对亚里士多德理论的怀疑态度是远远不够的[3]。
3.2 达尔文
下一个故事是达尔文(1809 - 1882)如何借助经济学理论完成了“自然选择物种进化”。
达尔文使用原始经验主义和降维来构建他的理论。在他之前,科学界并不存在对于基因和DNA的定义,他唯一拥有的是一个庞大的数据库,里面是他通过观察鸽子和自然界动植物所收集来的数据,仅通过研究鸽子的数据,他就推断出了进化论三大要素中的的两个。
1.自然变异
2.变异可以遗传
作为一名鸽子育种者,达尔文利用这两个要素来选择理想的性状,然后依靠人工杂交来培育新的鸽子品种。幼鸽从父母那里获得了一些特征,但是实质上这些特征都是来自“达尔文的选择”,而不是自然选择。有很长一段时间,达尔文并不知道自然选择的原理是什么。然后,他阅读了托马斯·马尔萨斯(Thomas Malthus)的《人口原理对社会未来进步的影响》(An Essay on the Principle of Population as It Affects the Future Improvement of Society)。马尔萨斯在书中描写了一场斗争,这场斗争是因人口繁殖速度超过食物产量增速而引发的。在此前提下,食物的可得性制约着人口数量,个体需要为生存斗争。马尔萨斯这方面的论证为达尔文提供了他缺失的那块拼图:从生存斗争中产生的自然选择。出生的婴儿数量超过了食物所能喂养的数量。达尔文(1859)的引言部分将其第三个基本原则归功于马尔萨斯。
3.物竞天择
一些杰出的博弈论者和经济学家现在经常使用进化论作为经济和社会动力的来源。也许他们认为是从达尔文那里得到了启发,但实际上达尔文理论的一个重要部分是从经济学家那里得到的。正如哈耶克(2011 年版,附录 A)指出的,达尔文1838年对亚当·斯密的研究为他提供了生物进化自然选择理论的一个关键组成部分。哈耶克(2011)还指出,文化进化论早在1800年之前就已被经济学家和社会学家广泛接受。
达尔文的研究策略是一个从庞大数据库中提取出具有通用性规律的很好的例子。数据收集,利用三个基本要素进行数据降维,最后进行理论概括:多么非凡的研究策略!
像伽利略一样,达尔文也不是从零开始。他在生物学、地质学和经济学方面都很博学。对这些领域的深刻理解是他能够突破已知、进行创新的基础。他是一个“宏观”的人,因为他的理论的前两个支柱,即自然变异和变异遗传,并没有“微观基础”。他的对于进化论三要素需要多长时间才能够与生物学已知的证据相符合,他也说得很模糊[4]。
人工智能
上文都在谈论人类的智慧和灵感,现在让我们转向人工智能或机器学习。它是什么呢?
我所说的人工智能是指模仿人类完成一些“智能”事情的计算机程序。“机器学习”主要是通过使用微积分和统计来完成模式识别。参照伽利略运用斜面实验测量下落物体速度的方法,设计者开发出能够进行机器学习和人工智能的计算机芯片和程序。因此,将函数视为“如果-那么”语句的集合。将“如果”部分想象为函数 y=f(x)中的横坐标 x,并将“那么”部分想象为y纵坐标。使用计算机识别模式涉及:(1)将数据划分为x和y部分,(2)猜测f的函数形式,然后 (3)使用统计的方法从不同的x和y数据中推断f。“统计学”这门学科提供了用于推断或“拟合”函数f的工具。
举一个简单的例子。假设在地球上的给定位置,在一年中的每一天都记录了从日出到日落的“白天”长度,在x轴上按照1到365记录天数,在y轴上记录从日出到日落的时长,制作一个以x和y为两列的表格。该表有365乘以2等于730个数字。现在绘制并凝视它们。猜测函数y=cos(α+βx)也许能很好地总结这些数据。使用微积分求使函数拟合得很好的两个参数α,β的值,它们最小化了下式:
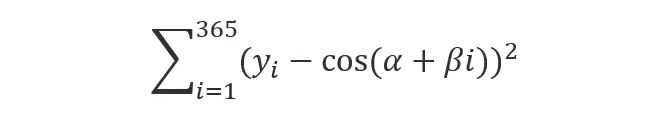
你会发现这个函数拟合得很好(尽管不完美)。通过总结数据(也可称为进行“数据压缩”或“数据缩减”),我们得以找出了一个经验法则(一个函数)来“概括”我们的发现,并可以使用这个法则来预测365天样本以外的 “白天”时长。
人工智能工具
机器学习和人工智能的核心方法来自以下学科[5]:
1.物理学
2.生物学
3.统计学
4.经济学
接下来我们将逐一分析这四个学科。
5.1 物理学
欧拉(Euler)、拉格朗日(Lagrange)和汉密尔顿(Hamilton)在18世纪和19世纪的研究成果扩充和完善了运用微积分最优化时变函数的积分方法。这为21世纪哈密顿蒙特卡罗(Hamiltonian Monte Carlo)的模拟技术奠定了基础,该技术继而推动了复杂的贝叶斯估计和机器学习的技术发展。克劳修斯(Clausius)、玻尔兹曼(Boltzmann)和吉布斯(Gibbs)在19世纪创造了用统计学来描述热力学的概念。他们根据熵定义了热力学第二定律,熵是似然比的期望值,即一个概率分布与另一个概率分布的比率。其中一个概率分布是一个平坦的均匀分布,它在统计上代表完全无序,另一个分布则在精确的、统计学意义上代表“有序”。在20世纪末和21世纪初,熵为许多机器学习算法提供了一种测量拟合模型的概率分布与数据经验分布之间差异的方法。保罗·萨缪尔森 (Paul Samuelson) (1947) 和他的同事们将这些技术和其他技术从数学物理学引入经济学,这将为人工智能和机器学习更多工具的发展奠定基础。
5.2 数学生物学
生物学从时间和空间上研究物种的繁殖和变异模式。模式可以从“宏观”和“微观”层面上检测,这取决于研究的单位——个人、动物、DNA、RNA,或组成它们那些更小的分子。生物学的数学理论(例如,费尔德曼(Feldman,2014) 和 费尔森斯坦(Felsenstein,1989)通过以随机差分或微分方程的形式构建动态系统来将这些模式构成数学体系。在微观层面,主要涉及将DNA编码为二进制字符串,以便分析师在该字符串上通过切割和重组进行突变和有性生殖的数学运算。例如,参见霍兰德(Holland,1987)。
5.3 统计学
现代数理统计认为“概率”有两种可能的含义[6]:
• 频率论者认为,概率是在观察一个非常大的独立且同分布的随机变量样本后可以预期的相对频率。
• 贝叶斯解释,概率是关于未知隐藏“状态”或“参数”的不确定性的主观表达。
现代统计学运用一系列工具来:(1) 制定一个函数集,这些函数的具体形式取决于一系列参数,有时参数还取决于更高层的超参数;(2) 从样本中推断或“估算”这些参数;(3) 以一个理性人的角度,描述这些推断的不确定性;(4)使用这些拟合函数的概率版本进行“样本外”预测。这些也是机器学习的基本技术,它们依赖于对微积分的应用,正如我们之前提过,伽利略当时并没有这些工具。
5.4 经济学
经济学是研究人类群体如何有目的地利用和分配稀缺资源的学科。现代经济理论是自洽环境中的多人决策理论。在一致的经济模型中的抽象智能人是“理性的”,因为他们处理有限优化问题皆基于他们对自身所处环境的共同、正确的理解[7]。这种多人决策理论的两个主要类别是博弈论和一般均衡理论[8],这二者都对机器学习和人工智能的发展意义非凡。
这些理论中的主要因素和内容包括:
• 约束
• 不确定性
• 去中心化和并行优化
• 交易网络的账本
• 价格
• 竞争
在这些模型中,一个个体的决策规则构成了其他个体选择问题的约束集的一部分。这种约束通过模型的 “均衡条件”产生。个体约束优化问题的解中,可以导出个人价值,其中包含用以分配资源的有用信息。
这些经济模型描述了“并行处理” 和去中心化的决策过程。一个被称为“均衡”的安排有助于调和不同个体之间的自私决策以及物理资源的限制。严格的均衡概念在这两个主流框架中占据主导地位。定义均衡是一件事,计算均衡则是另一回事。因此,著名的经济理论家们多年来一直在与维度的诅咒斗争、寻求计算竞争均衡分配和价格体系的可靠方法。对这一事业做出了里程碑意义的贡献的经济理论家有艾罗与赫维克兹(Arrow and Hurwicz,1958)、艾罗(Arrow et al.,1959)、艾罗(Arrow,1971)、二阶堂与宇泽(Nikaidˆo and Uzawa,1960)以及斯卡夫(Scarf,1967)、斯卡夫(Scarf et al.,2008)。这些算法运用了计算方案,追踪个人和社会价值量,以及人们想要的商品和活动的数量与社会安排之间的差距。
计算均衡的研究工作最终发现,均衡的计算与有限理性个体向均衡的收敛之间具有密切联系。布瑞与克雷普斯(Bray and Kreps,1987)以及马赛特与萨金特(Marcet and Sargent,1989)提出了“在均衡中学习”和“学习均衡 ”之间的重要区别。马赛特与萨金特(Marcet and Sargent,1989)和萨金特(Sargent et al.,1993)通过使用随机近似的数学方法(例如,见格拉迪夫(Gladyshev,1965))来研究向理性预期均衡的收敛。据我所知,关于随机近似的最初工作始于霍特林(Hotelling,1941)、傅利曼与萨维奇(Friedman and Savage,1947)。他们试图构建一种统计抽样方法,来精确地解出一个未知函数在给定点的最大值[9]。
舒比克(Shubik,2004)和巴克(Bak et al. ,1999)的相关工作构建了一些博弈,他们利用这些博弈来思考价格制定者对均衡过程的促进作用。(在一般均衡模型中,只有价格接受者,没有价格制定者)。舒比克的工作运用了他对一个课题的专业知识,这个课题存在于一般均衡理论和博弈论的夹缝中,对机器学习和人工智能有重要意义,它就是:
• 货币理论
本着舒比克(Shubik,2004)的精神,思考货币理论的一个好方法是,注意到它的目的是解释均衡价格向量是如何被实际生活在一般均衡模型中的个体设定的。艾罗和德布鲁(Debreu)的经典一般均衡模型描述了均衡价格向量的特性,但对谁来设定这个价格向量以及如何设定却保持沉默。相反,一个模型之外的“神灵”神秘地宣布了一个价格向量,同时出清了所有的市场。一个均衡价格向量保证了每个个体的预算约束得到满足。在一般均衡模型中,贸易是多边的,预算约束在一个中心化的账户中得到协调。相反,货币理论是关于一个分散的系统,该系统中的人们只是偶尔在一系列双边会面中见面,并通过使用“交换媒介”交换商品和服务。交换媒介可以是耐用金属(金或银)、代币(便士、纸质“美元”或“英镑”)、流通的债务凭证,或者银行、清算所或中央银行的账目条目。奥斯特罗伊与斯塔(Ostroy and Starr,1974),奥斯特罗伊与斯塔(Ostroy and Starr,1990),以及最近的汤森(Townsend,2020)总结了该流派的研究。加密货币理论是这些研究的直系后代。
我再介绍一下博弈研究对机器学习的贡献。几十年来,应用经济学家已经构建了计算博弈均衡的算法,支撑这些计算的关键工具包括逆向归纳法(动态规划)和树状搜索。由于要研究的可能状态的维度呈指数增长,减少要研究状态的数量对于在近似均衡方面取得进展至关重要。在这方面,minimax算法和α-β剪枝搜索算法是主要的方法,可参考克努斯与摩尔(Knuth and Moore,1975)的著作和https://www.youtube.com/watch?v=STjW3eH0Cik,可以了解α-β剪枝搜索的描述,并看到相应的计算系统和“适者生存”的想法。一条相关的研究路线研究了一群天真地基于对手过去的行动进行优化的玩家是否会收敛到纳什均衡。可参见蒙德勒与沙普利(Monderer and Shapley,1996),霍夫鲍尔与桑德霍尔姆(Hofbauer and Sandholm,2002),福斯特与杨(Foster and Young,1998),弗得伯格(Fudenberg et al.,1998)。当收敛成立时,这种 "虚构游戏 "算法提供了一种计算均衡的方法,可参见兰伯特三世(Lambert Iii et al. ,2005)。
5.5 约翰·霍兰德(John Holland)在约1985年提出的人工智能愿景
著名的计算机科学家约翰·霍兰德10是一位先驱者。他结合了我们提到的所有技术领域的思想,为生活在给定环境中的决策者构建了计算机模型。在这种环境中,决策者别无选择,只能按照艾罗(Arrow,1971)的思路,“在实践中学习”。霍兰德(Holland,1987)介绍了他的这一方法,马里蒙(Marimon et al.,1990)描述了在多人经济环境中的具体应用。霍兰德方法的一个重要部分是全局搜索算法,他称之为“遗传算法”。它通过用字符串表示函数的参数来搜索“崎岖不平的景观”,这些字符串可以被随机匹配成一对字符串,并进行切割和重新组合。这是霍兰德表示“性繁殖”的机械方式。这样的“遗传算法”包含了他所说的“分类器”系统的一部分。霍兰德的分类器系统包括:(1)一连串的“如果-那么”语句,其中一些必须相互竞争,以获得在线(即实时的)决策权。(2)一种将“如果-那么”语句编码为二进制字符串的方法,该字符串可以进行随机突变、切割和重组;(3)一个为单个“如果-那么”语句分配奖励和成本的计算系统;(4)破坏和创建新的“如果-那么”语句的程序,包括基于DNA切割和重组的随机突变和有性繁殖;以及(5)一种筛选出适合决策规则的竞争性斗争。霍兰德分类器系统已经被证明能够学会在动态环境中保持耐心,就像拉蒙·马里蒙(Ramon Marimon)总结的那样,在由霍兰德的人工智能个体组成的世界中,“耐心需要经验”。霍兰德分类器成功地计算出了一个动态经济模型的“稳定”纳什均衡,该模型的作者们事先并没有意识到这个均衡的存在,尽管事后,他们能够验证霍兰德分类器交给他们的“猜测”(Marimon et al.,1990)。
5.6 当今的人工智能
DeepMind的计算机程序AlphaGo实现了一项了不起的成就,它成功地掌握了围棋游戏,并打败了人类围棋冠军选手(Wang et al.,2016)。AlphaGo的创造者所采用的方法让我想起了美食的烹饪过程——在一把原料中加入一丁点另一种原料,品尝一下,再加入其他原料……在烹饪AlphaGo的成分中,包含了一系列经济学和统计学的方法,比如动态规划、汤普森采样(见汤普森(Thompson,1933))随机逼近(见霍特林(Hotelling,1941)、傅利曼与萨维奇(Friedman and Savage(1947))、α-β树搜索(见克努斯与摩尔(Knuth and Moore(1975))、Q-学习(见沃特金斯和达扬(Watkins and Dayan(1992))、蒙特卡洛树搜索(见布朗(Browne et al.(2012))。参数调整的经验法则选择是很重要的,它可以在“探索”和“利用”之间进行权衡(弗得伯格与克雷普斯(Fudenberg and Kreps,1993)、(Fudenberg and Kreps(1995)中也是如此论述的)。
机器学习的其他最新进展也引入了大量经济学和统计学的方法。计算最优运输问题(例如,佩雷(Peyr´e et al.(2019))使用丹齐格(Dantzig)、康托罗维奇(Kantorovich)和柯普曼斯(Koopmans)的线性程序来衡量理论概率和经验测量之间的差异。然后,它使用该衡量方法来构建一种高效的计算方式,以匹配数据和理论。经济学家霍特林(Hotelling,1930)用黎曼几何来表示统计模型的参数化系列。这个想法开启了计算信息几何学的先河,阿玛里(Amari,2016)将这种方法系统化了。
创造力的来源:模仿和创新
我描述了伽利略和达尔文是如何通过对前人研究结果和方法的掌握,并将其与前所未有的洞察力相结合,从而发现新的自然规律。这两位做出卓著贡献的天才科学家的共同特点是对先例的尊重,以及他们冒险超越的能力。后来许多天才也采用了同样的方法,如电磁学的发现,以及富兰克林(Franklin)、戴维(Davy)、法拉第(Faraday)、麦克斯韦(Maxwell)、迈克尔逊(Michaelson)、莫利(Morley)、爱因斯坦(Einstein)的一系列发现。他们每个人都不是从“白板”(凑巧的是,这恰好是上述平克著作的标题)开始,而是从他们对前人的深刻理解和尊重开始的。每个人都看到了他们的前辈没有看到的东西,往往是因为他们采用了改进的观察或推理方法。通过运用法拉第不知道的数学,麦克斯韦组织了一个令人惊叹的统一和概括,将电磁动力学的法则减少到12个方程,而海维斯德又很快将它减少到四个方程。这四个方程为爱因斯坦的狭义相对论创造了条件[11]。
看似与电磁学毫不相关的纯理论数学,却与后来电磁学的发现恰好吻合。为了将几何学转换为代数并写成函数,笛卡尔(Descartes)发明了一个坐标系统。50年后,牛顿和莱布尼茨利用笛卡尔坐标系发明了微分和积分。十九世纪上半叶,高斯(Gauss)和他的学生黎曼(Riemann)完善了基于平行线相交的曲面几何。里奇(Ricci)在此基础上增加了一个明确的曲率概念。
爱因斯坦将这两个独立的、看似“豪不相关”的研究工作结合起来,一个是实际的物理现象,另一个是纯粹的抽象数学。爱因斯坦在努力扩展其狭义相对论时,学会了如何使用黎曼几何和里奇曲率,构建了一个自洽的广义相对论[12]。
科学进步展示了“模仿”和“创新”两者之间的互动,这种互动在现代经济增长理论中也有所体现(例如,见班哈波柏(Benhabib et al.,2014)和班哈波柏(Benhabib et al.,2020))。在“模仿”阶段,电磁学、相对论和数学领域的先驱者主要是复制前辈和老师的技术;在“创新”阶段则是在某种程度上超越前辈和老师,因为他们比老师学得更多、理解得更深。
结论性评述
通过对物理学、生物学、统计学和经济学中的主要思想的概述,我希望佐证我的主张:即这些平克Pinker(2003)认为人类在认知上有先天局限的学科,正是被用来创造人工智能和机器学习的学科。无论你是在校生还是已经离开学校,这是应该学习这些学科的又一个理由。在我看来,它们自身的美则构成了另一个理由。
(参考文献略,详情请点击此处查看英文论文原文)
编辑:北大汇丰智库
